更新日:
【初心者向け】Terraformの使い方を徹底解説!

Terraformとは、インフラ構成をコードで管理し、自動的に作成・変更・削除できる「IaC(Infrastructure as Code)」ツールです。
Terraformとは
TerraformはInfrastructure as Code(IaC)ツールです。
つまり、AWS や GCP などのクラウド環境で作るサーバやネットワークなどを、コードとして記述して管理することができます。
(例)
- EC2 インスタンスを 1 台作る
- S3 バケットを作る
- VPC やサブネットを作る
もちろん、従来のようにAWSやGCPの管理画面からサービスを作成することも可能です。しかしこの方法には、次のような課題があります。
- 時間がかかる(10台のサーバーを作るなら10回同じ操作が必要)
- ミスが起きやすい(途中で設定を誤る可能性がある)
- 記録が残らない(どんな設定をしたか後で確認できない)
- 再現が難しい(全く同じ環境を作り直すのが困難)
そこでTerraformを利用すれば、以下のメリットが得られます。
- 何百台のサーバーでも一度で作成できる
- 全く同じ環境を何度でも再現できる
- 設定変更も簡単 ・チーム全員で設定を共有できる
Terraformのインストール
複数のプロジェクトで異なるTerraformバージョンを使い分けるため、tfenv(Terraformバージョン管理ツール)の使用を強く推奨します。
tfenvとは
tfenvはTerraformのバージョンを簡単に切り替えられるツールです。プロジェクトごとに異なるバージョンを使用でき、チーム開発で統一されたバージョンを保つのに役立ちます。
tfenvのインストール
以下のコマンドでtfenvをインストールします。
1
2
3
4
brew install tfenv
# バージョン確認
tfenv --version
次にtfenvを使い、Terraformをインストールします。
まずは利用可能なTerraformのバージョンを確認します。
1
tfenv list-remote
次に特定のバージョンをインストールします。今回は1.133.3をインストールするので以下のコマンドを実行します。環境によって異なるので、事前に確認してから行いましょう。
1
2
3
4
5
# Intel CPUやx86_64環境では以下のコマンド
tfenv install 1.13.3
# M1/M2 MacやARM対応Linuxなどは以下のコマンド
TFENV_ARCH=arm64 tfenv install 1.13.3
次にインストール済みのバージョンを確認します。
1
tfenv list
バージョンを確認したら、使用するバージョンを決定します。
1
tfenv use 1.13.3
最後に指定したバージョンになっているか確認をします。
1
terraform version
これでインストールの完了です。
Terraformの基本ファイル
Terraformでは、主に以下のファイルを使います。
ファイル名は必ずしもこの名前でなければいけないというわけではありませんが、可読性や管理のしやすさのために、一般的には以下のように分けます。
| ファイル名 | 役割 |
|---|---|
| main.tf | メインのリソース定義 |
| variables.tf | 変数定義 |
| terraform.tfvars | 変数に値を渡すファイル |
| outputs.tf | 出力情報の定義 |
他のファイルも同様で、必ずこのファイル名にしなければいけないなどのルールはありません。自分や第三者がわかりやすい名前をつけるようにしましょう。
これらのファイルの中でterraform.tfvars や、後に作成されるterraform.tfstateといったファイルは秘密情報が含まれるため、絶対にGitにコミットしないでください。.gitignoreに必ず以下のコードを記述しておきましょう。
1
2
3
4
5
6
7
8
9
# Local .terraform directories
**/.terraform/*
# .tfstate files
*.tfstate
*.tfstate.*
# .tfvars files
*.tfvars
Terraformの基本構造
Terraformは.tf拡張子のファイルで設定を記述し、HCL(HashiCorp Configuration Language)という専用の言語を使用します。HCLはJSONに似ていますが、コメントが書けたり、可読性が高いのが特徴です。
Terraformのコードはブロック単位で構成されます。基本形は以下です。
provider構文
どのクラウドサービス(AWS、GCP、Azureなど)を使うかを指定します。例えばAWSであれば以下のようになります。
1
2
3
4
5
provider "aws" {
access_key = "AWSのアクセスキー"
secret_key = "AWSのシークレットアクセスキー"
region = "AWSのリージョン"
}
resource構文
実際に作成するクラウドリソース(サーバー、データベース、ネットワークなど)を定義します。
1
2
3
4
5
6
7
8
9
10
resource "リソースタイプ" "リソースを参照するための名前" {
設定1 = "値1"
設定2 = "値2"
}
// (例)AWSのS3のバケットを作成
resource "aws_s3_bucket" "example" {
bucket = "my-first-bucket"
acl = "private"
}
上の例であれば以下のように記述します。
・aws_s3_bucket
→ リソースタイプ(サービスの種類)
・example
→ Terraform内の名前
・{ } の中身 → 細かい設定
リソースタイプはTerraformが用意しているリソースの種類なので、自分で好きな名前をつけることはできません。
名前(上のコードだとexample)は自由につけられます。名前はTerraform内の識別用に使われます。複数の同じリソースタイプを作る場合に区別するために使います。プロパティはリソースタイプに応じて指定します。リソースごとの具体的な書き方は公式ドキュメントで確認ができます。
変数の使い方
Terraformでは変数を使うことが出来ます。
変数はvariables.tfファイルに定義します。ここでは、変数が何のためのものかの説明と変数の型などを指定します。値はまだ代入しません。
{ }の中には、下記の3つ以外にもプロパティが存在します。また、必ずしもすべてのプロパティを定義する必要はありません。その場合は、次のステップで必ず値を代入する必要があります。
typeを定義しない場合は、どんな型でも代入可能です。基本的にはdescriptionとtypeを付けておくのが推奨されます。
1
2
3
4
5
variable "変数名" {
description = "変数の説明"
type = 変数の型
default = "値が渡されなかった時のデフォルト値"
}
例えば、バケット名を変数名で管理したい場合は以下のように記述します。
1
2
3
4
5
6
7
8
9
// 例
variable "bucket_name" {
description = "S3 bucket name"
type = string
default = "my bucket"
}
// 例 以下のようにプロパティを省略しても問題ないが、必ず値を代入する必要がある
variable "bucket_name" {}
これで変数の定義ができました。次はterraform.tfvarsで変数に値を代入させます。
1
2
3
4
変数名 = "代入する値"
//例
bucket_name = "my-first-bucket"
呼び出す時は以下のように記述します。文字列の中で使う際は${ }で囲みます。
1
2
3
4
5
6
7
8
9
10
11
12
13
var.変数名
// 例
resource "aws_s3_bucket" "example" {
bucket = var.bucket_name // 「my-first-bucket」がbucketに代入される
acl = "private"
}
// 文字列の中で使う時
resource "aws_s3_bucket" "example" {
bucket = "${var.bucket_name}-bucket" // 文字列内で変数を使っているので「${ }」で囲む
acl = "private"
}
Terraformの基本コマンド
この章ではTerraformの基本的なコマンドを紹介します。
初期化
Terraformを使える状態にするためのコマンドです。
初めてTerraformを使う際に、必ず実行する必要があります。
1
terraform init
構成の確認
コードで定義した内容が、クラウド上で何をするのかを確認できます。
クラウド上に反映させる前に、このコマンドで確認をしておきましょう。
1
terraform plan
デプロイ
ファイルに書いたコードを元に、実際にクラウド上にリソースを作成します。
1
terraform apply
実行後は確認メッセージが出るので、yesと入力します。
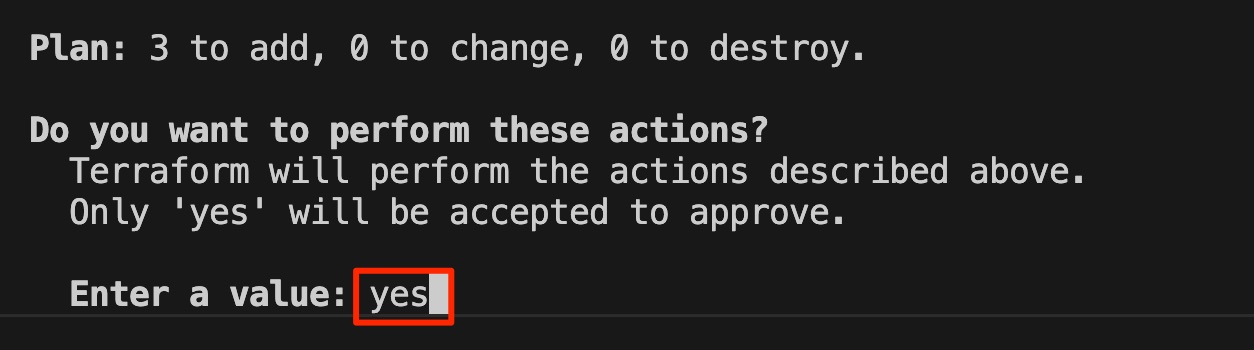
デプロイ後にはterraform.tfstateというファイルが作成されます。terraform.tfstateは Terraformが管理しているインフラの「現状」を記録する状態ファイル です。
Terraformは「設定ファイル(.tf)」と「この状態ファイル」を比較して、どのリソースを新規作成・変更・削除すべきかを判断します。
重要なファイルですので、手動で削除・編集・Git管理をすることは絶対に避けましょう。
破棄
作成したリソースを削除します。実行後は確認メッセージが出るので、yesと入力します。
1
terraform destroy
現在の状態の確認
terraform applyコマンド実行後に作られたリソース がどんな状態になっているかを確認できます。
1
2
3
4
5
# 標準出力に、現在のリソース一覧と設定値が表示される
terraform show
# JSON形式で出力される
terraform show -json
AWSを使う場合の設定
プロバイダーでAWSを使いたい時は以下のように記述します。ファイル名は任意ですが、provider.tfなどわかりやすい名前にしておきましょう。access_keyとsecret_keyは流出しないよう変数として定義しておきましょう。
1
2
3
4
5
provider "aws" {
access_key = var.aws_access_key
secret_key = var.aws_secret_key
region = "ap-northeast-1" // 自分のリージョンを指定
}
アクセスキーとシークレットキーは右上の自分のユーザー名をクリックすると表示される「セキュリティ認証情報」をクリックします。
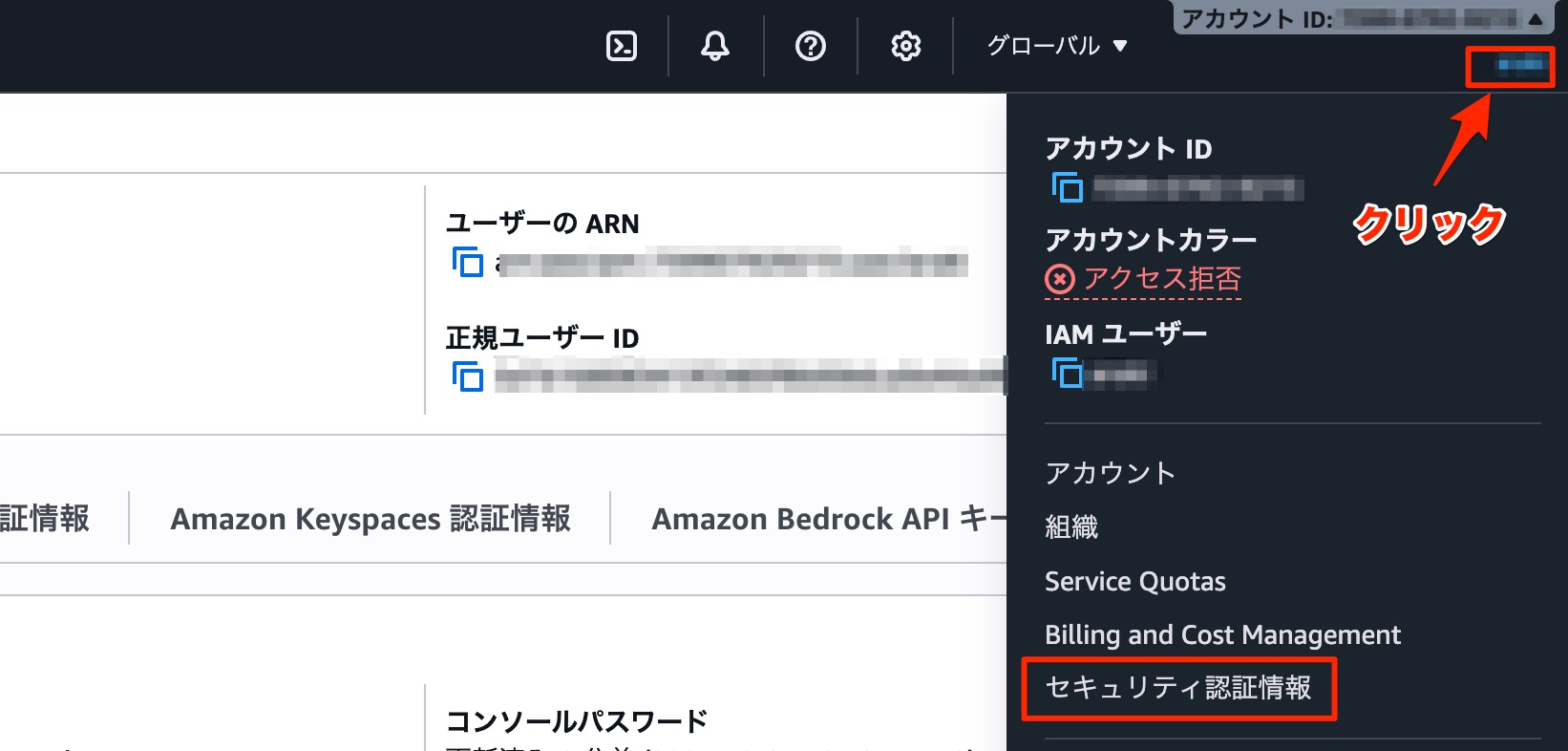
遷移したページの「アクセスキー」で「アクセスキーを作成」をクリックします。

ユースケースで「コマンドラインインターフェイス(CLI)を選択し、表示されるチェックボックスにチェックを入れ、次へをクリックします。
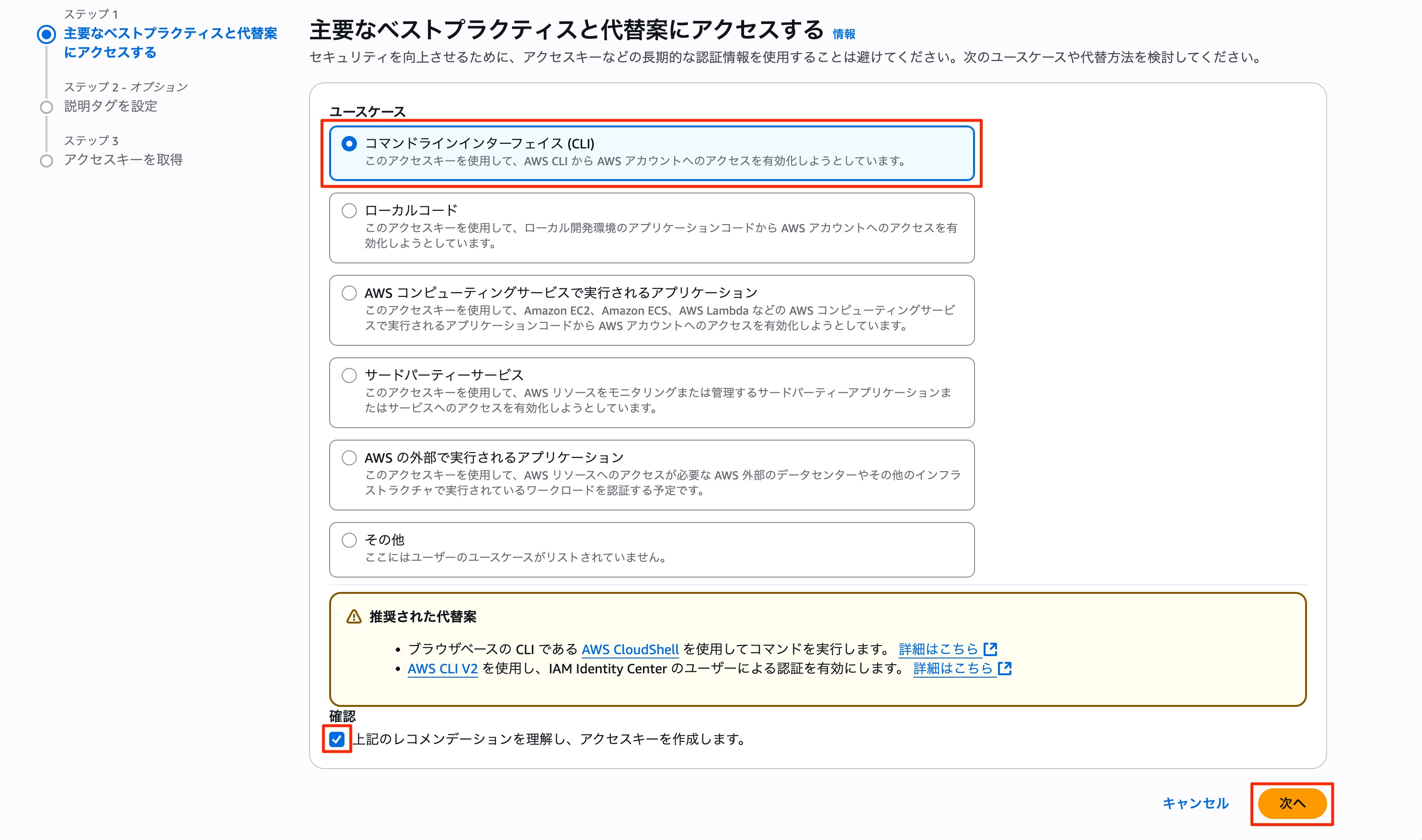
次に説明タグを設定します。「Terraform-test」など管理しやすい名前をつけておきましょう。最後に右下の「アクセスキーを作成」をクリックします。

すると以下のような画面になります。
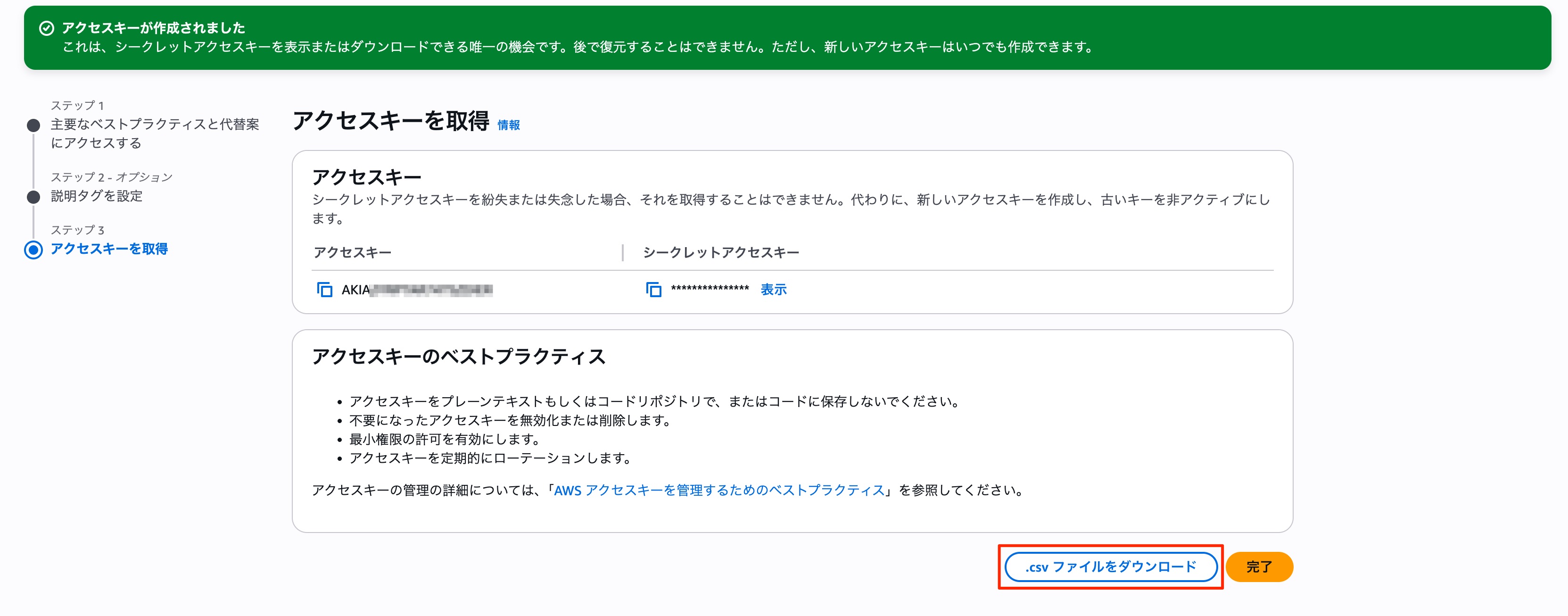
この画面を閉じてしまうと二度とシークレットアクセスキーが確認できなくなってしまうので、必ず「.csvファイルをダウンロード」をクリックし、ファイルをダウンロードしておきましょう。
ここで表示されているアクセスキーとシークレットアクセスキーを変数に代入しておきましょう。

実際に作成する流れ
この章では実際にAWS上にサービスを作成するまでの流れを解説していきます。
例えばS3にバケットを作成するとします。最初は書き方がわからないので、公式ドキュメントを参考にしながらコードを記述していきます。
以下がコードの一例です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// S3バケット本体を作成
resource "aws_s3_bucket" "my_first_bucket" {
bucket = "my-unique-bucket-name-20250105"
tags = {
Name = "私の最初のバケット"
Environment = "学習用"
ManagedBy = "Terraform"
}
}
// バケットのバージョニング設定
resource "aws_s3_bucket_versioning" "my_first_bucket_versioning" {
bucket = aws_s3_bucket.my_first_bucket.id
versioning_configuration {
status = "Enabled" // ファイルの履歴を保存
}
}
// バケットの暗号化設定
resource "aws_s3_bucket_server_side_encryption_configuration" "my_first_bucket_encryption" {
bucket = aws_s3_bucket.my_first_bucket.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256" // 標準的な暗号化
}
}
}
一行ずつ解説していきます。
1.S3バケットの作成部分
1
resource "aws_s3_bucket" "my_first_bucket" {
この部分は公式ドキュメントの「aws_s3_bucket」を参照し、作成しました。
resourceは「サービスを作る」という宣言です。次のaws_s3_bucketで「AWSのS3バケット」を作成すると指定します。my_first_bucketはTerraform内での名前なので、好きな名前をつけることができます。
1
bucket = "my-unique-bucket-name-20250105"
bucketはAWS上に作成する実際のバケット名になります。この名前は全世界で一意である必要があります。
バケット名の後に日付などをつけておくと良いでしょう。
1
2
3
4
5
tags = {
Name = "私の最初のバケット"
Environment = "学習用"
ManagedBy = "Terraform"
}
tagsはラベルのようなもので、後で管理しやすいように付けておくものです。
2.バージョニング設定
1
2
resource "aws_s3_bucket_versioning" "my_first_bucket_versioning" {
bucket = aws_s3_bucket.my_first_bucket.id
aws_s3_bucket_versioningはS3のバージョニングの設定を作成します。この部分はこの公式ドキュメントを参考に作成しました。
バージョニングとはファイルの履歴を自動保存する機能です。同じファイル名で保存すると、通常は上書きされ、前に保存していたファイルは消えてしまいます。ですが、バージョニングを有効にしておくと上書きしても過去の全バージョンが自動で保村されます。
aws_s3_bucket.my_first_bucket.id の部分は先ほど作ったバケットの参照です。my_first_bucketは1行目で名付けたTerraform内での名前です。Terraformではこのようにして簡単に参照できるのが便利なところです。
1
2
3
versioning_configuration {
status = "Enabled"
}
この部分はファイルを上書きしても、古いバージョンを保持する設定です。
3.暗号化設定
1
2
3
4
5
6
7
8
9
resource "aws_s3_bucket_server_side_encryption_configuration" "my_first_bucket_encryption" {
bucket = aws_s3_bucket.my_first_bucket.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256" # 標準的な暗号化
}
}
}
aws_s3_bucket_server_side_encryption_configurationは暗号化するときに使います。
ruleブロックのapply_server_side_encryption_by_defaultはデフォルトのサーバー側の暗号化(SSE)をするためのものです。
sse_algorithmは仕様するサーバー側の暗号化アルゴリズムを指定します。
今回はこのコードのみしか記述しませんでしたが、他にもアクセス制限(バケットポリシー)を付けたい場合はそのコードを追加します。
このように公式ドキュメントを参考にコードを作成します。
このコードを使い、実際にAWS上にS3を作成する流れは以下のようになります。
s3.tfなどの名前でファイルを作成し、公式ドキュメントを参考にリソースを書くterraform initで初期化terraform planで確認terraform applyで作成- AWSのS3 コンソールで確認
terraform initコマンドは毎回実行する必要はありません。ただし以下のような場合は実行する必要があります。
・ 新しくTerraformプロジェクトを作成したとき
・ 新しいプロバイダーを追加・バージョン変更したとき
実際にAWSのS3のコンソールでバケットができているか確認をすると、以下のようにしっかりと作成されています。
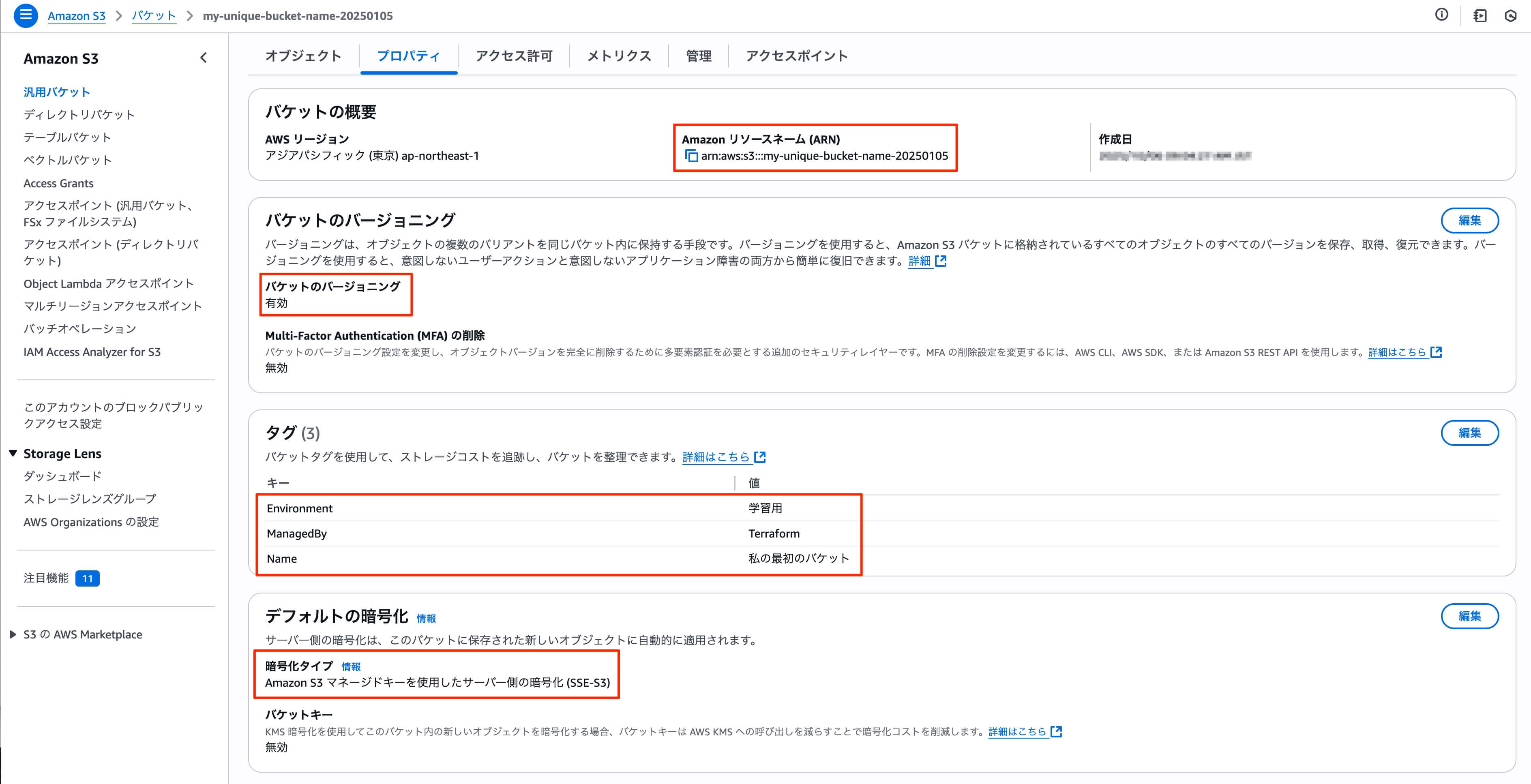
data構文の使い方
先ほどのコードで、作成したバケットのidを取得する際は、aws_s3_bucket.my_first_bucket.idのようにして、Terraform内で使える名前を参照することが出来ました。しかし、もしTerrraformでバケットを作成せず、AWSのコンソールからバケットを作成すると、このような書き方はできません。
そういった時はdata構文を使い、idなどのデータを取得する必要があります。
1
2
3
4
5
6
7
8
9
10
11
12
data "aws_s3_bucket" "existing_bucket" {
bucket = "already-created-bucket-name" // AWSに存在する実際のバケット名を指定
}
// 参照したバケットに設定を追加
resource "aws_s3_bucket_versioning" "existing_bucket_versioning" {
bucket = data.aws_s3_bucket.existing_bucket.id // dataで参照
versioning_configuration {
status = "Enabled"
}
}
最初に記述したdata構文を解説します。
1
data "aws_s3_bucket" "existing_bucket" {
dataは既存リソースを参照するという宣言です。aws_s3_bucketは参照するサービス名を指定します。existing_bucketはTerraform内での名前なので、好きな名前をつけます。
1
bucket = "already-created-bucket-name"
この部分はAWS上の参照したいバケット名を書きます。
AWS上に存在しない名前だとエラーになります。
1
bucket = data.aws_s3_bucket.existing_bucket.id
dataで始めることでAWS上に作成されたリソースを参照すると指定し、aws_s3_bucketでサービス名を、existing_bucketは先ほど作成した、Terraform内の名前を指定します。このように書くことで、今回であればAWS上に存在するalready-created-bucket-nameという名前のバケットのidを取得することが出来ます。
まとめ
Terraformは最初は難しく感じるかもしれませんが、基本を知ってしまえば思っているより簡単に書くことが出来ます。AWSなどで新たなサービスを作成する際はぜひTerraformを使ってみましょう。
この記事のまとめ
- Terraformはインフラ構成をコードで管理できる ツールです。
- 差分を自動で適用して、必要な変更だけを反映できます。
- マルチクラウド対応で、AWSやGCPなど複数の環境を一元管理できます。
