更新日:
【IT用語】 「文字コード」とは?実はコンピューターの基幹部分!

文字コードとは、アルファベットやひらがな等の文字をビット列(0と1の組み合わせ)に対応させた規格です。ASCIIコードやUTF-8など、様々な種類があります。

文字コードとは何か
まず、そもそも文字コードは一体何なのでしょうか。
ここでは文字コードの仕組みについての解説と、文字コードによって起こる文字化けについての説明を行います。
文字コードの仕組み
コンピューターは0と1しか認識できません。
ではなぜ画面上に日本語や英語が表示できているのか、考えたことはあるでしょうか。
なぜ文字コードは存在するのか
画面上に文字を表示するには0と1の組み合わせを文字として認識する仕組みが必要です。
なので、その組み合わせ(ビット列)に対して、例えば「010011=あ」「010100=い」...として処理しましょうと決め、必要な文字とビット列の対応関係を定めたものが文字コードです。
もし文字コードが存在しなければ、アルファベットも打てないのでまともにプログラムを書くことすらできないでしょう。
それほどまでに文字コードはコンピューターにおける基幹的な部分なのです。
また、文字コードには様々な種類が存在し、010011がaや글となっていたりと対応関係が異なります。
文字コードを使う
それでは、実際に文字コードがどのように使われているか説明します。
文字コードをUTF-8というものに決め、画面上で「ぴかわか」と打つと、コンピューターの内部では「e381......818b」(16進数 例えば、eは1110)として扱われていることになります。

ここで、別のコンピューターにこのデータを送信します。
そこでもUTF-8に合わせて文字を表示すれば、元の「ぴかわか」の文字列が得られます。
コンピューターが変わっても、UTF-8という変換器が同じなら同じ文字を表示させることができるのです。
なぜ文字化けは起こるのか?
一度は文字化け
という言葉を聞いたことがあると思います。
webサイトなどが、「譁�ュ怜喧縺�」のような意味不明でホラーな文字の羅列で埋め尽くされてしまう現象です。
この文字化けの原因は、文字コードにあります。
文字化けが起こる理由
先ほどはUTF-8で打った文字を、同じUTF-8で表示したので正しい文字が得られました。
ここで、間違えてShift-JISという文字コードで表示してしまうとどうなるでしょう。
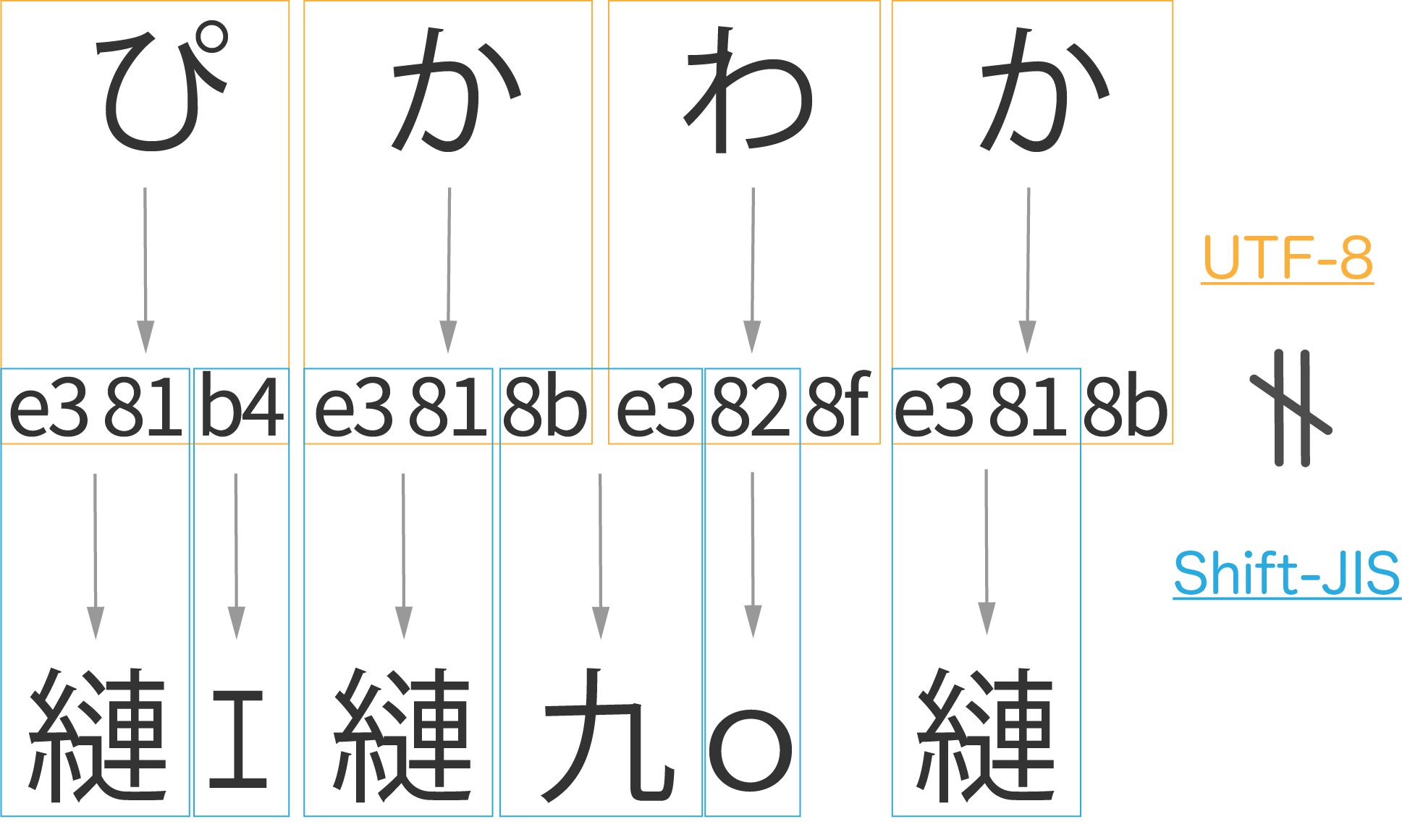
このように、文字コードが一致していないと文字化けが起こってしまいます。
UTF-8では「ぴ」に対応するe381b4
が、Shift-JISでは「縺」と「ェ」に対応しているのが原因です。
文字化けを起こしてみよう
では実際に、Safariを使って文字化けを意図的に起こしてみましょう。
PikawakaはUTF-8で書かれています。なので、ブラウザ側の文字コードをShift-JISに設定すれば文字化けが起こるはずですが、どうなるでしょう。
まず、SafariでPikawakaのサイトを開きます。

サイトを開いたら、下のようにメニューバーの「表示」→「テキストエンコーディング」→「日本語(Shift JIS)」でSafari側の文字コードをShift-JISに変更します。

すると、想定通り文字化けを起こすことができました。

なぜ文字コードを一つにしないのか
ここまで読んだ方は、文字化けが起こるなら文字コードを統一すべきと思われるかもしれません。
では、不具合が起こるのにもかかわらず多くの文字コードが利用されているのはなぜでしょう。
ここで、日本語を入力する際の文字コードについて考えてみましょう。
webサイトで日本語の記事を書く場合、好ましい文字コードは、日本語が含まれており、かつ少ないビット列で効率よく表現できるShift-JISなどの文字コードです。
では逆に、日本語を全く使わないサイトでは、日本語が優先されているShift-JISを用いる意味はありません。
このように、シチュエーションによって適切な文字コードが異なるので、いろいろな文字コードが使用されているのです。

文字コードの仕組みや文字化けの概要についておさらいしてきましたが、これ以上詳細な内容を学ぶ際はこういった専門書を読むとよいでしょう。
文字化けさせないwebサイトを作る
文字化けは回避できないものではなく、HTMLを書く際にサイトが文字化けを起こさないよう対策すれば、文字化けをなくすことは可能です。
1
<meta http-equiv="content-type" charset="utf-8">
このように、meta要素に文字コードを明示しておくことで、ブラウザの勘違いを未然に防ぐことができます。
代表的な文字コード
ここまでの説明で、文字コードについては理解していただけたかと思います。
以降は、よく使われている代表的な文字コードを挙げて解説します。
ASCIIコード
ASCIIコードは最も基本的な文字コードです。非常に多くのコンピューターが対応しており、最も互換性が高いという特徴があります。
最も基本的というだけあって、ASCIIコードにはアルファベットと少しの記号を合わせた128文字しか存在しません。
1バイト(256通り)で全て表現できるため、1バイト文字(1バイトで1文字)のみの文字コードとなっています。
また互換性の高さを生かし、これに文字を追加して拡張したASCIIコードの派生文字コードが多く存在します。
Shift-JIS
Shift-JISはASCIIコードをベースに日本語の文字を追加した文字コードで、日本語を扱う際に最も一般的に使われています。
英数字と半角カナを1バイトで、ひらがなと漢字を2バイトで表します。
こうすると文字の区切りが分からなくなってしまいそうですが、Shift-JISは2バイト文字かどうかが1バイト目でわかる、賢い設計になっています。
後述するUTF-8と比較して日本語をより少ないビット数で表現できるため、日本語だけに特化した文字コードであるといえます。
UTF-8
UTF-8は、現在世界で最も一般的に使われている文字コードで、これもASCIIコードの拡張コードです。
UTF-8の特徴は、圧倒的な文字種の多さです。
Unicodeという、世界中の文字を扱うための基準に合わせた設計になっており、あらゆるシチュエーションに対応できるのが強みです。
UTF-8は基本的に1~4バイトの範囲で文字を表します。
またASCIIコード互換なので、よく使われるアルファベットは1バイトと効率よく表現できます。
UTF-16
UTF-16も、UTF-8と同じ、Unicode準拠の文字コードです。
UTF-8との違いは、文字によってビット数が変化しない固定長(2または4バイト文字)になっていることです。
日本語においてはUTF-8よりも短く(効率よく)表せるようになっています。
この記事のまとめ
- 文字コードとは、ビット列を文字に対応させた規格で、様々な種類がある
- 正しい文字コードでデコードしないと文字化けが起こる
- 世界中の文字を扱うために定めたUnicodeに則ったUTF-8がよく使われている
