AIの主な技術
このカリキュラムではAIの主な技術についての基本的な知識を学びます。
機械学習とは

機械学習と聞くと難しく感じるかもしれませんが、実際には私たちの日常生活に密接に関わっています。たとえば、スマートフォンの顔認証や動画プラットフォームでのおすすめ動画の提案など、身近な場所で機械学習が活用されています。これらすべてが機械学習の成果です。
機械学習は、コンピュータが学校で学ぶように勉強する方法です。人間が新しいことを学ぶとき、先生が教えたり、本を読んだりしますが、コンピュータも機械学習を通じて同じように学びます。
コンピュータが学習するために使用する写真や情報は「データ」と呼ばれます。データが多ければ多いほど、コンピュータはより賢くなります。
機械学習は、コンピュータに大量のデータを与えて学習させ、新しいデータについて予測や判断を行う技術です。人間が一つ一つ教えるのではなく、コンピュータ自身がデータからパターンを見つけ出して「学習」します。
機械学習の種類
機械学習には大きく分けて3つのタイプがあります。
1. 教師あり学習
教師あり学習とは、AIが「先生に教わりながら学ぶ方法」です。この方法では、AIに多くの例(データ)とその答え(ラベル)を見せます。例えば、犬の写真と「これは犬です」というラベル、猫の写真と「これは猫です」というラベルを使って、AIに犬と猫の違いを学ばせます。
教師あり学習は、特に正確な答えが必要な場面で非常に効果的です。例えば、医療の分野での病気の診断、メールのスパムフィルタリング、音声認識など、私たちの日常生活の多くの場面でこの学習方法が使われています。AIが正しい答えを出せるようになることで、多くの作業が自動化され、効率が向上します。
2.教師なし学習
通常、学校で学ぶときは先生が正しい答えを教えてくれます。例えば、数学の問題を解くとき、先生は「これが正しい方法です」と教え、間違えた場合には「ここが間違っています」と指摘してくれます。しかし、教師なし学習では、AIは正解を教えてもらうことなく、多くの情報から自分でパターンやルールを見つけ出します。
この学習方法は、正解がわからない問題に非常に役立ちます。例えば、顧客データから似た特性を持つ顧客グループを作成し、マーケティング戦略をより効果的に計画することができます。世の中には、すぐに答えがわからない難しい問題がたくさんありますが、教師なし学習を使うことで、AIはこれらの問題に対しても自分で解決策を見つけることができるようになります。
3. 強化学習
エージェント(AI自身)は環境内(活動する場所)で行動を選び、その行動に対する環境の反応(報酬またはペナルティ)を観察します。そして、次の行動を選択するための最適な方策を決定するというサイクルを繰り返します。
このようにして、AIに「ご褒美をもらいながら最適な選択をする方法」を教えることで、さまざまなスキルが向上していきます。ゲームのAIが徐々に上達していくのは、この強化学習のおかげです。
ディープラーニングの世界

この章では、AIの最も革新的な分野の一つであるディープラーニングに焦点を当てます。この単元を通じて、ディープラーニングの基本概念、その背後にある数学的原理、そして実際の応用例について学びます。
ディープランニングとは
ディープラーニングは、AIの分野の中でも特に注目されている技術の一つです。これは、機械学習の一形態であり、データから学習することで、人間の脳の働きを模倣しようとする多層ニューラルネットワークに基づいています。

ディープラーニングの基本概念
ディープラーニングは、複数の隠れ層を持つニューラルネットワークを用いて、入力データから複雑な特徴やパターンを抽出することができます。これにより、画像認識、音声認識、自然言語処理など、従来の機械学習モデルでは困難だったタスクを高い精度でこなすことができるようになります。
ディープランニングの歴史
ディープラーニングの研究は数十年前に遡りますが、大量のデータ処理能力と計算能力の向上により、2010年代に入ってから急速に発展しました。特に、GPUの使用による計算速度の向上が、ディープラーニングの進化を加速させました。
ディープラーニングの応用分野
ディープラーニングは、以下のような多岐にわたる分野で応用されています。
- 画像認識・処理
- 音声認識・合成
- 自然言語処理
- 自動運転車
- 医療診断
これらの応用によって、ディープラーニングは私たちの生活を豊かにし、多くの産業に革命をもたらしています。
ディープラーニングの進化はまだ始まったばかりであり、これからも新しい技術の発見や応用分野の広がりが期待されています。
ニューラルネットワークの基礎
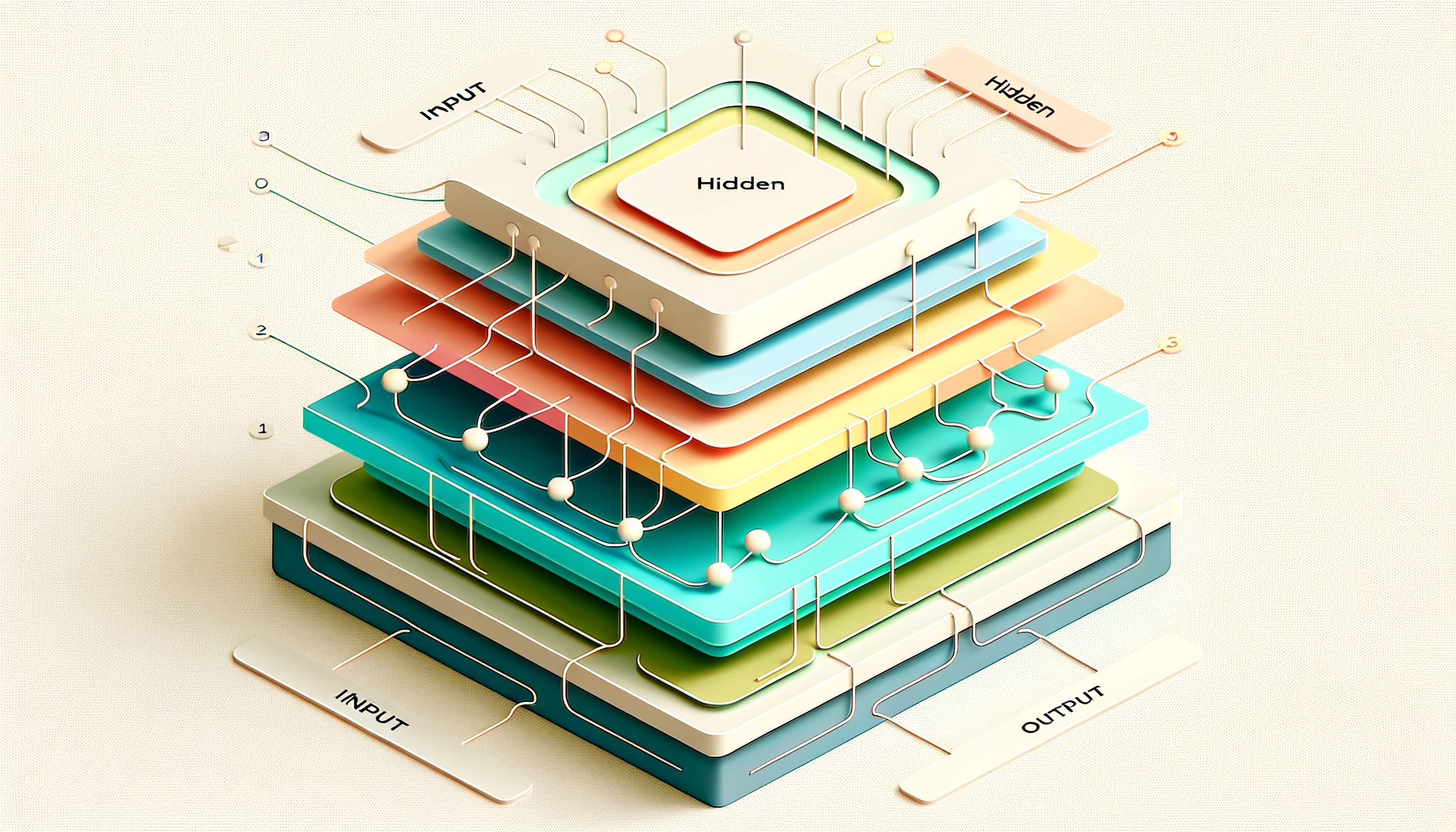
ニューラルネットワークは、ディープラーニングの基盤となる技術です。これは人間の脳の働きに似ているため、こう呼ばれています。人間の脳には多くの神経細胞があり、情報を受け取り、処理し、次に何をすべきかを決めます。
ニューラルネットワークも同様に、多くの小さな部品がつながっています。これらの部品は「ノード」と呼ばれ、それぞれが小さな計算を行います。ノードがたくさんつながり、情報を受け取って答えを出すのを助けます。
例えば、コンピュータに犬の写真を見せて、「これは犬ですか?」と質問すると、ニューラルネットワークは多くのノードを使ってその写真が犬かどうかを判断します。最初は間違えることもありますが、多くの写真と答えを学習することで、徐々に正しい答えが出せるようになります。
ニューラルネットワークの構造
ニューラルネットワークを「学校のクラス」に例えてみると、以下のような構造になっています。
入力層(Input Layer)
データをネットワークに入力する層で、学校の入り口のようなものです。ここから情報(例えば、犬の写真や数字)がニューラルネットワークに入ってきます。入力層は情報を受け取る役割を持っています。
隠れ層(Hidden Layers)
入力層と出力層の間にある層のことを言います。これは、学校の教室のように生徒たち(情報)が学び成長する場所です。隠れ層は一つだけでなく、複数存在することが一般的です。各層は前の層から情報を受け取り、新しいことを学んだり、計算したりして、次の層に情報を送ります。これらの層が多ければ多いほど、ニューラルネットワークはより複雑なことを学ぶことができます。
出力層(Output Layer)
最後に、学んだすべての情報が「出力層」に送られます。これは学校の出口のようなもので、ニューラルネットワークが最終的にどんな答えを出すかを決定する場所です。例えば、「この写真は犬ですか、猫ですか?」という質問に対して、「犬です」と答えるかもしれません。
ニューラルネットワークの中では、各層のノード(小さな計算単位)が「重み」と呼ばれる数値でつながっています。これは情報が次の層にどれだけ影響を与えるかを決める重要な要素です。学校で言うと、どの先生(ノード)がどの生徒(情報)にどれだけ影響を与えるかに相当します。
このようにして、ニューラルネットワークは情報を受け取り、それを加工して、最終的な答えを出すというプロセスで動いています。
活性化関数(Activation Functions)
ニューラルネットワークにおける活性化関数は、各層のノード(生徒)がどのように「反応」するかを決定するルールです。具体的には、この関数がないと、各ノードは入ってきた情報をそのまま次の層に渡してしまいます。活性化関数は、その情報が「どれだけ重要か」を判断し、次の層にどれだけの情報を渡すかを決める役割を持っています。
活性化関数の役割
活性化関数は、ニューロンの出力を決定する重要な役割を果たします。非線形性を導入することで、ネットワークが複雑な問題を学習できるようにします。
1. 非線形性の導入
人間の脳も、すべての情報を同じように処理するわけではありません。重要な情報には強く反応し、重要でない情報にはあまり反応しないことがあります。活性化関数は、ニューラルネットワークにも同様に、情報に対する「反応の強さ」を加えることで、より複雑で有用な処理を可能にします。
2. 情報のゲートキーパー
クラスでの発表を考えてみましょう。先生が「この質問には、明確な答えを用意してください」と指示する場合、学生は自分の考えをきちんと整理してから発表します。活性化関数も同じように、どの情報が次の層に伝えられるべきかを決めるルールのようなものです。
一般的な活性化関数
一般的な活性化関数には以下のものがあります。
シグモイド関数(Sigmoid)
0から1の間の値を出力する関数で、確率的な判断が求められる時に使われます。例えば、「この画像は猫ですか?」と聞かれた時に、どれくらい確信しているかを0から1のスケールで示します。
ReLU(Rectified Linear Unit)
ReLU関数は、ニューラルネットワークでよく使われる活性化関数の一つです。この関数の役割は非常にシンプルで、入力された値が0以下であれば0を出力し、0より大きければその数値をそのまま出力します。これを使うことで、ネットワークが無駄な計算を避け、効率的に動作するのを助けます。例えば、数学のテストで0点以下の得点はあり得ないので、0点を下回る計算結果はすべて0として扱い、無駄な処理を省きます。
Tanh(ハイパボリックタンジェント)
Tanhは、入力された数値を-1から1の範囲に変換する関数です。この変換により、ニューラルネットワークが扱う数値は常に一定の範囲内に収まります。これによって、ネットワークの学習がより安定し、特に入力値の大きさが異なる場合に効果的です。
例えば、野球の試合で15-0で勝った場合と3-2で勝った場合、通常は15-0の勝利の方が高く評価されます。しかし、Tanhを使うと、どちらの勝利も1として処理されます。負けた場合は-1、引き分けは0といったようにデータを均一に変換することで、より安定した学習と予測が可能になります。
これらの活性化関数は、ニューラルネットワークが複雑な問題を解決するのを助けるために、それぞれ異なる特性を持っています。ニューラルネットワークの学習や反応の仕方を向上させるために、これらの関数は重要な役割を果たしています。
学習プロセス
ニューラルネットワークの学習プロセスは、基本的に以下のステップで構成されます。
- 順伝播(Forward Propagation): ニューラルネットワークが情報を入力から出力へと伝えるプロセスです。これをゲームで例えると、キャラクターが敵に挑戦することに似ています。プレイヤー(ニューラルネットワーク)は、どの攻撃を使うか(出力)を決めるために、敵の情報(入力)を見て判断します。
- 損失関数(Loss Function): ニューラルネットワークがどれだけ間違えたかを測る方法です。ゲームでいうと、戦いが終わった後に得たスコアが目標スコアにどれだけ近いかを確認することです。目標スコアからどれだけ離れているかが「損失」で、これが大きいほど、プレイヤーのパフォーマンスが悪かったということになります。
- 逆伝播(Backpropagation): 損失関数を使って、ニューラルネットワークが次回より良い結果を出せるように学習するプロセスです。ゲームで例えるなら、戦いが終わった後にプレイヤーが自分の間違いを振り返り、どのスキルを改善すべきかを考えることに似ています。これによって、次の戦いでより良い戦略を立てることができます。
- 最適化アルゴリズム(Optimization Algorithms): 逆伝播で見つかった改善点を実際に適用して、ネットワーク全体をより良くする手順です。ゲームでいうと、新しいスキルや装備を使ってキャラクターをアップグレードすることで、次の戦いに備えるのに似ています。
ニューラルネットワークは、これらの基本的な要素とプロセスを通じて、データから複雑な関係性やパターンを学習することができます。これがディープラーニングを強力なツールとしている主な理由の一つです。
ディープラーニングの課題と未来
ディープラーニングは、AI技術の中でも特に大きな進歩を遂げた分野ですが、いくつかの課題があります。これらの課題を克服するための研究が進められており、将来的にはさらなる可能性が期待されています。

ディープラーニングの課題
ディープランニングの課題として以下のものがあります。
1. データの依存性とバイアス
ディープラーニングモデルは、大量のデータを必要としますが、そのデータが偏っていると、予測結果にバイアスが生じることがあります。公正なAIシステムを実現するためには、バイアスのないデータセットを構築することが重要です。
2. エネルギー消費
複雑なディープラーニングモデルは大量の計算リソースを消費し、それに伴い大量のエネルギーを必要とします。環境への影響を考慮し、よりエネルギー効率の高いAI技術の開発が求められています。
3. 説明可能性
ディープラーニングモデルは「ブラックボックス」と見なされることが多く、その決定過程を理解することが難しい場合があります。説明可能なAI(XAI)の研究は、モデルの決定根拠を明らかにし、信頼性を高めることを目指しています。
4. 一般化と適応性
特定のタスクやデータセットに対して最適化されたモデルが、他の異なるタスクや環境にも適応できるとは限りません。より汎用的なAIモデルの開発が重要な課題となっています。
ディープラーニングの未来
ディープラーニングの未来として以下のようなものが期待されています。
1. フェデレーテッドラーニング
ユーザーのプライバシーを保護しながら、分散されたデータから学習を行う手法です。この方法では、データを一箇所に集めるのではなく、各デバイスやサーバーがそれぞれの場所でデータを保持し、学習を行います。その結果得られた情報だけを中央のサーバーに送信することで、プライバシーを守りながらより公平なモデルを構築することが可能です。
2. エネルギー効率の良いAI
新しいアルゴリズムやハードウェアの開発により、より少ないエネルギーで動作するディープラーニングモデルの実現が期待されています。
3. ニューロモルフィックコンピューティング
人間の脳の構造を模倣したコンピューティング技術です。より自然な学習プロセスと高いエネルギー効率を実現することが期待されます。
4. トランスファーラーニングとメタラーニング
一つのタスクで学んだ知識を別のタスクに応用する技術(トランスファーラーニング)や、学習方法そのものを学ぶ技術(メタラーニング)によって、より汎用的で適応性の高いAIの実現が目指されています。
ディープラーニングの未来は、これらの課題を克服し、より効率的で公正、そして人間と共生する形でAI技術が発展することが期待されています。
AIの応用
AIの応用範囲は、今日では非常に広く、多岐にわたっています。以下に、AIが特に影響を与えている主な分野を紹介します。
1. 自然言語処理(NLP)
AIは、テキストや音声データから意味を抽出し、理解する能力を持ちます。これには、機械翻訳、音声認識、チャットボット、感情分析などが含まれます。NLP(Natural Language Processing)の進化により、人間とコンピュータ間のより自然な対話が可能になっています。
2. 画像認識とコンピュータビジョン
AIは顔認識、物体検出、画像分類など、ディープラーニングは画像から情報を抽出する能力を大幅に向上させました。これは、セキュリティシステム、自動運転車、医療画像診断など多くの分野で使用されています。
3. 推薦システム
オンラインショッピングや動画ストリーミングサービスでは、AIを使った推薦システムが、ユーザーの好みや行動履歴に基づいて、関連する商品やコンテンツを提案します。これにより、ユーザーエクスペリエンスが向上しています。
4. 自動運転
AIは、センサーデータの解析、物体の認識、意思決定などを行うことで、自動運転技術の核心部分を担っています。自動運転車は、交通の安全性と効率性を大幅に改善する可能性があります。

5. 医療診断
AIは、画像診断、遺伝子データの解析、疾病予測など、医療分野での診断の精度とタイムリーさを向上させるために使用されています。これにより、より正確で迅速な診断が可能になり、パーソナライズされた治療計画の策定が支援されます。

6. 金融業界
AIは、不正検知、クレジットスコアリング、自動取引システムなど、金融分野における多くのアプリケーションで使用されています。これにより、リスク管理が強化され、顧客サービスが向上しています。

7. 製造業とサプライチェーン
AIは、生産プロセスの最適化、品質管理、需要予測など、製造業やサプライチェーン管理において重要な役割を果たしています。これにより、効率が向上し、コストが削減されています。
AIの応用は、これらの分野にとどまらず、教育、エンターテインメント、農業、環境保護など、私たちの生活のさまざまな面に影響を与えています。AI技術の進化に伴い、その応用範囲はさらに広がり、社会に大きな変革をもたらすことが期待されています。
このカリキュラムのまとめ
重要なポイントをおさえよう!
- 機械学習は、コンピュータに大量のデータから学習させ、新しいデータについて予測や判断を行わせる技術
- ディープラーニングは、AIの分野の中でも特に注目されている技術の一つ
- ニューラルネットワークは、ディープラーニングの基盤となる技術
この記事で学んだことをTwitterに投稿して、アウトプットしよう!
Twitterの投稿画面に遷移します