スクレイピング
スクレイピングは、Webサイトに記載されている情報をプログラミングを使って取得する技術のことです。
このカリキュラムでは、Railsの mechanize というgemを活用してスクレイピングの使い方を学習します。
このスクレイピングの章は、以下の手順で進めます。
- Railsアプリケーションの作成とGemの導入
- スクレイピングを使ってWebページのデータを取得しよう
- スクレイピングで取得したデータをDBに挿入しよう
Railsアプリケーションの作成とGemの導入
それでは、このカリキュラムで利用するRailsアプリケーションを作成しましょう。
以下のコマンドを実行して下さい。
1
rails new mechanize_slack_app
次に mechanize という gem をインストールしましょう。
Gemfile に以下を追記して下さい。
1
gem 'mechanize'
Gemfileの追記が終われば、 bundle install を実行し gem を取り入れましょう。
スクレイピングの基本的な使い方
この章では、スクレイピングの基本的な使い方を学びます。
スクレイピングの基本的な使い方は、【Rails】 Mechanizeを使ってスクレイピングをしよう のページを参考にしましょう。
Webページのタイトルの取得
先ほど作成した mechanize_slack_app に移動して、以下のコマンドを打ち込んで下さい。
1
touch lib/web_scraper.rb
作成した web_scraper.rb に以下の内容を入力して下さい。
1
2
3
4
5
6
7
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
end
まず rails c のコマンドを使い、rails consoleを立ち上げましょう。
1
rails c
コンソールに以下を入力して、Pikawakaサイトのサイトタイトルを取得できれば完了です。
1
2
irb(main):001> WebScraper.get_title('https://pikawaka.com')
=> "Pikawaka - ピカ1わかりやすいプログラミング用語サイト"
それでは get_title メソッドを使用して、任意のWebサイトを三つ選び、タイトルを取得しましょう。
タイトルの取得方法は Webページのタイトルの取得方法の参考ページ を参考にして下さい。
Webページに記載されている指定した要素のテキストを取得
次にWebページに記載されている指定した要素のテキストを取得します。要素 を指定するには searchメソッド を使い、要素のテキストを取得するには inner_textメソッド を使用します。
指定した要素のテキストの取得方法の例として、h1要素のテキストを取得するメソッドを作ってみましょう。
1
2
3
4
5
6
7
8
9
10
11
12
13
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
def self.get_h1_text(url)
agent = Mechanize.new
page = agent.get(url)
page.search('h1').inner_text
end
end
get_h1_text を活用し、任意のWebサイトを三つ選び、それぞれのサイトのh1のテキストを取得しましょう。
※ h1を設定していないサイトに関しては、空文字が取得されます。
「任意の要素をテキスト」を取得するメソッドを作成しよう
次に特定のページの「任意の要素をテキスト」を取得するメソッドを作成しましょう。
例えば、以下の画像を見るとPikawakaトップページのサイドバーにあるカテゴリーは c-sidebar__article-title クラスの要素の中の a 要素で取得できることが分かります。
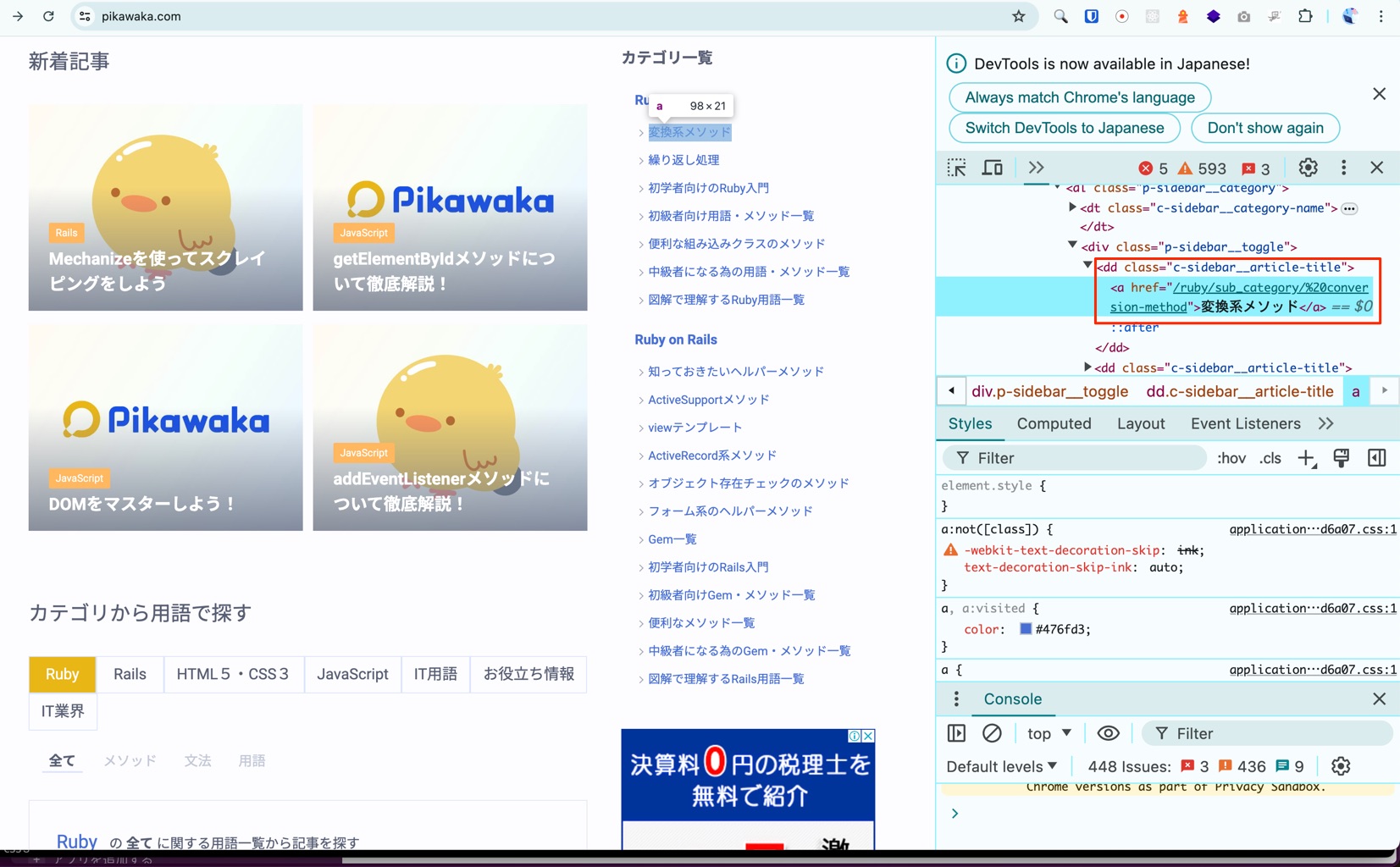
「Pikawaka」という特定のページのサイドバーにあるカテゴリーの全てをテキストを取得するには、以下のようなメソッドを作成する必要があります。以下のメソッドを web_scraper.rb に追記して下さい。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
def self.get_h1_text(url)
agent = Mechanize.new
page = agent.get(url)
page.search('h1').inner_text
end
def self.get_pikawaka_sidebar_category_texts
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('.c-sidebar__article-title', 'a').each do |element|
texts << element.inner_text
end
puts texts
end
end
メソッドを実行し、以下のように表示されていることを確認して下さい。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
irb(main):026> WebScraper.get_pikawaka_sidebar_category_texts
変換系メソッド
繰り返し処理
初学者向けのRuby入門
初級者向け用語・メソッド一覧
便利な組み込みクラスのメソッド
中級者になる為の用語・メソッド一覧
図解で理解するRuby用語一覧
知っておきたいヘルパーメソッド
...
get_pikawaka_sidebar_category_texts のように特定のWebページの任意のテキストを取得するメソッドを作成しましょう。
get_サイト名_コンテンツ名_texts の命名規則に従ってメソッドを作成して下さい。コンソールでメソッドを実行し、テキストを取得できているか確認して下さい。
指定した属性値を取得
次は属性値を取得する方法を学びます。まず a タグの href という属性値を取得する方法について学習します。
属性値の取得に関しては、こちらのサイトを参考にして下さい。
a タグの href という属性に https://pikawaka.com を入れた場合、以下のような表記になります。
<a href="https://pikawaka.com" target="_blank">https://pikawaka.com</a>
この要素の href 属性の値を取得するには、以下のように記述します。
1
2
a要素.get_attribute('href')
=> https://pikawaka.com
このようにaタグであれば href 属性を指定することで、aタグに設定されているリンクを取得できます。
imgタグであれば、 src 属性を指定することで、画像urlを取得できます。
それでは、以下のように「特定のページのサイドバーにあるカテゴリーのリンク」を全て取得するメソッドを追記しましょう。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
def self.get_h1_text(url)
agent = Mechanize.new
page = agent.get(url)
page.search('h1').inner_text
end
def self.get_pikawaka_sidebar_category_texts
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('.c-sidebar__article-title', 'a').each do |element|
texts << element.inner_text
end
puts texts
end
def self.get_pikawaka_sidebar_category_links
url = 'https://pikawaka.com'
agent = Mechanize.new
page = agent.get(url)
links = []
page.search('.c-sidebar__article-title', 'a').each do |element|
link = element.get_attribute('href')
links << url + link if link.present?
end
puts links
end
end
メソッドを実行し、以下のように表示されていることを確認して下さい。
1
2
3
4
5
6
7
8
9
10
11
irb(main):026> WebScraper.get_pikawaka_sidebar_category_links
https://pikawaka.com/
https://pikawaka.com/ruby
https://pikawaka.com/rails
https://pikawaka.com/html-css
https://pikawaka.com/javascript
https://pikawaka.com/word
https://pikawaka.com/tips
https://pikawaka.com/it-industry
...
get_pikawaka_sidebar_category_links のように、特定のWebページの任意の属性値を取得するメソッドを作成しましょう。
Slack通知機能
Slack通知機能は特定のアクションを実行した際にSlackへ通知する機能のことを指します。
Slack通知機能の導入
ここではテスト用として、卒業生コミュニティチームで自身に通知するSlackチャンネルをまず作成しましょう。
slack_notification_宮嶋勇弥 のように slack_notification_自身のフルネーム でチャンネルを作成して下さい。
作成後にそのチャンネルに宮嶋を招待して下さい。
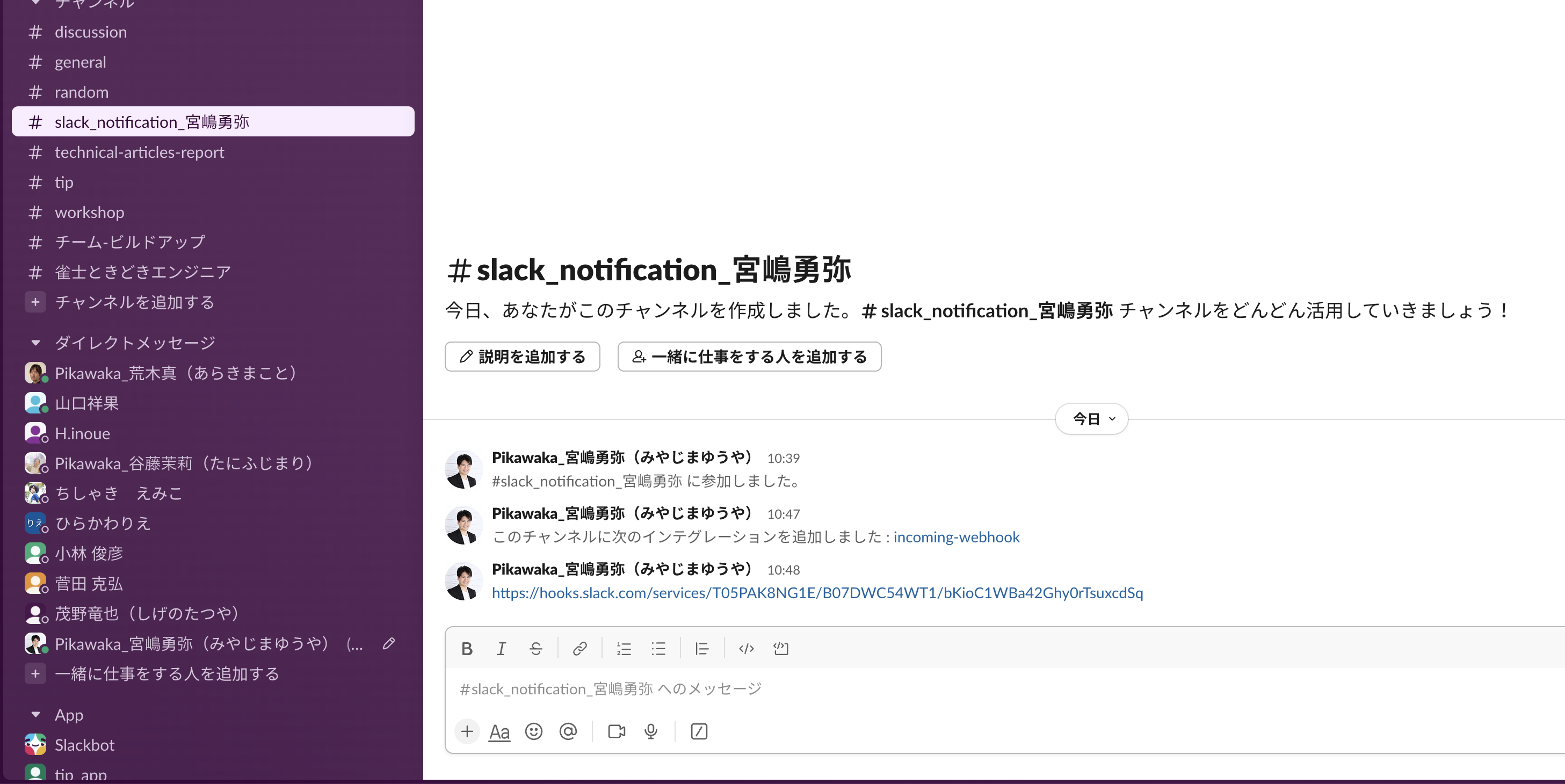
以下のサイトを参考に、slack_notification_自身のフルネーム を指定して Slack通知を受け取るためのWebhook urlしましょう。
https://pikawaka.com/rails/slack-api#incoming-webhookを追加しよう
Webhook urlを取得できれば、以下の画像のように Webhook url を送信して下さい。
Slack通知のGemを導入しよう。
1
2
gem "slack-notifier"
gem "dotenv-rails"
以下のサイトを参考に環境変数を定義して下さい。
https://pikawaka.com/rails/slack-api#環境変数を定義しよう
Slack通知機能の実装
準備は整いました。ここからSlack通知機能の実装を行っていきましょう。
rails c を実行し、コンソールを立ち上げて下さい。
コンソールを立ち上げたら、以下の内容を打ち込んで下さい。
1
2
3
4
5
6
notifier = Slack::Notifier.new ENV['WEBHOOK_URL'] do
defaults channel: "#workshop", #チャンネル名
username: "通知BOT" #Slackに表示するユーザー名
end
notifier.ping 'Hello workshop' # Slackに通知するメッセージ
すると #workshop へ 'Hello workshop' という内容の通知が届きましたね。
上記のように設定することで、指定したチャンネルに指定した内容が届くようになります。
scraping機能とslack通知機能を掛け合わせてみよう
scraping機能とslack通知機能のそれぞれの実装方法について学びました。
ここからはScraping機能とSlack機能を掛け合わせた機能を作成してみましょう。
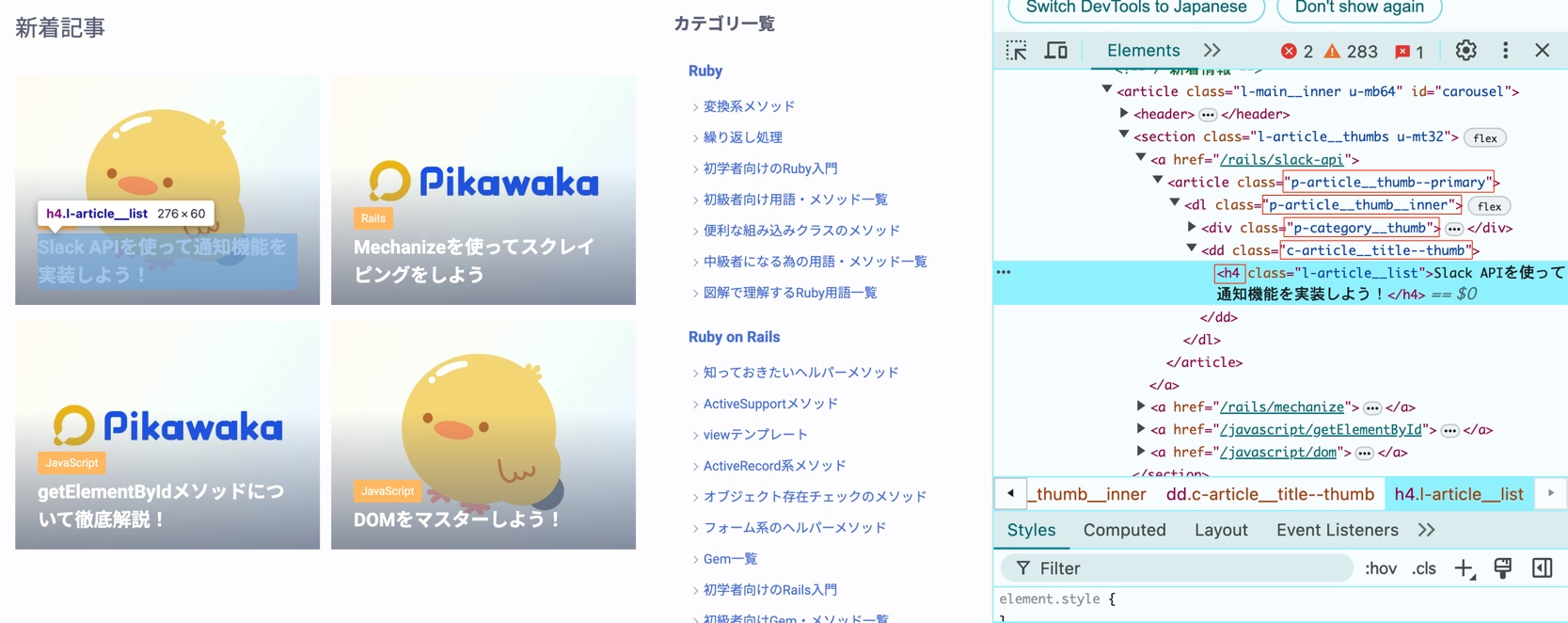
例としてPikawaka サイトに新規で作成された記事を取得し通知する方法を見てみます。
以下の画像を参考にすると新着記事は、p-article__thumb--primary クラスの中の p-article__thumb__inner クラスの中の c-article__title--thumb クラスの中の h4 要素であることが分かります。
以下のようにメソッドを追記して、新着記事を取得するメソッドを作成して下さい。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
def self.get_h1_text(url)
agent = Mechanize.new
page = agent.get(url)
page.search('h1').inner_text
end
def self.get_pikawaka_sidebar_category_texts
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('.c-sidebar__article-title', 'a').each do |element|
texts << element.inner_text
end
puts texts
end
def self.get_pikawaka_sidebar_category_links
url = 'https://pikawaka.com'
agent = Mechanize.new
page = agent.get(url)
links = []
page.search('.c-sidebar__article-title', 'a').each do |element|
link = element.get_attribute('href')
links << url + link if link.present?
end
puts links
end
def self.get_pikawaka_newest_article_links
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('p-article__thumb--primary', 'p-article__thumb__inner', 'c-article__title--thumb', 'h4').each do |element|
text = element.inner_text
texts << text
end
puts texts.first(4)
end
end
メソッドを実行すると、新着記事のタイトル一覧を取得できました。次にタイトル一覧をスラックチャンネルに通知するように修正します。
以下のようにメソッドを修正して、実行して下さい。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class WebScraper
def self.get_title(url)
agent = Mechanize.new
page = agent.get(url)
page.title
end
def self.get_h1_text(url)
agent = Mechanize.new
page = agent.get(url)
page.search('h1').inner_text
end
def self.get_pikawaka_sidebar_category_texts
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('.c-sidebar__article-title', 'a').each do |element|
texts << element.inner_text
end
puts texts
end
def self.get_pikawaka_sidebar_category_links
url = 'https://pikawaka.com'
agent = Mechanize.new
page = agent.get(url)
links = []
page.search('.c-sidebar__article-title', 'a').each do |element|
link = element.get_attribute('href')
links << url + link if link.present?
end
puts links
end
def self.get_pikawaka_newest_article_texts
agent = Mechanize.new
page = agent.get('https://pikawaka.com')
texts = []
page.search('p-article__thumb--primary', 'p-article__thumb__inner', 'c-article__title--thumb', 'h4').each do |element|
text = element.inner_text
texts << text
end
texts.unshift("【Pikawakaの新規記事一覧のタイトルを取得しました。】\n") # 配列の先頭に要素を追加
notifier = Slack::Notifier.new ENV['WEBHOOK_URL'] do
defaults channel: "#slack_notification_宮嶋勇弥", username: "通知BOT"
end
notifier.ping texts.first(4).join("\n") # Slackに通知するメッセージ
end
end
このようにスクレイピングで取得した情報をスラックに通知することで、スクレイピングとスラックを掛け合わせた機能を作成できました。
「任意のテキストを取得しよう」で作ったメソッドを修正して、スクレイピングで取得したテキストをスラックに投稿できるように修正してみましょう!
この記事で学んだことをTwitterに投稿して、アウトプットしよう!
Twitterの投稿画面に遷移します